
This article delves deeper into identifying signs of a compromised instance and provides guidance on responsive actions. In our increasingly perilous online landscape, these precautions are crucial to shield sensitive data and digital assets. Let’s explore essential measures for safeguarding your digital environment.
Common Indicators of Instance Compromise
This section explores practical warning signs that serve as early indicators of compromise, aiding in safeguarding digital assets. We’ll delve into specific signals such as unusual system behavior, performance issues, anomalous log entries, unexpected network patterns, and unauthorized access attempts. Recognizing and understanding these signs enables stronger defense mechanisms and effective responses to security threats.
1. Unusual System Behavior and Performance Degradation
Compromised systems often exhibit abnormal behavior and reduced performance as initial warning signs. These can include sluggish response times, unexpected crashes, or irregular resource utilization. For instance, on Linux-based systems, you can monitor system performance using the ‘top’ command:
topSimilarly, on Windows systems, utilize the Task Manager to inspect running processes and their resource usage.
To open it either search for “Task Manager” in the Windows search bar or press [CTRL] + [SHIFT] + [ESC] to access it.
It will look like this:
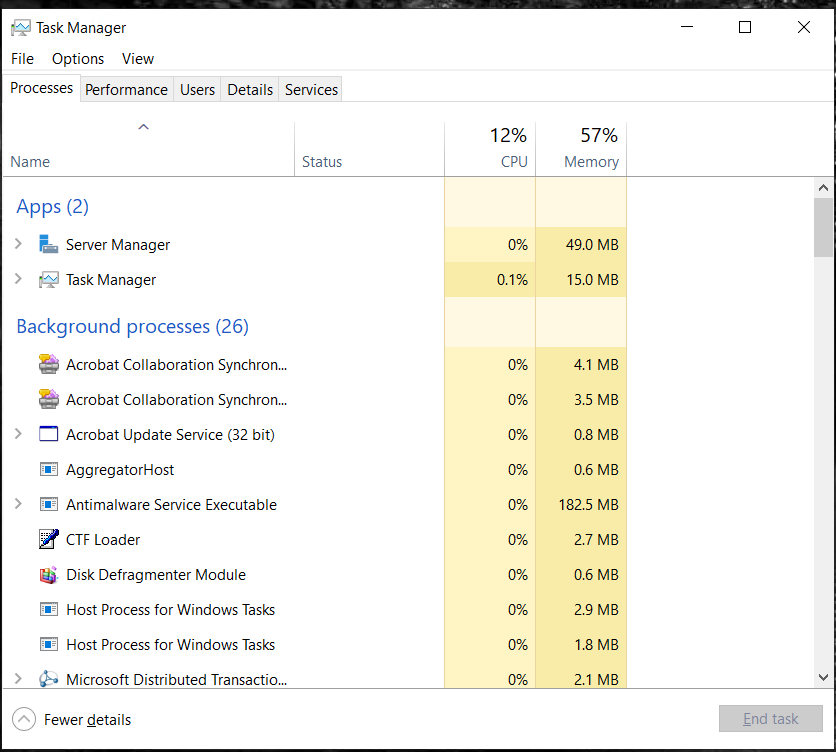
Here you can see all processes that are running – active and background ones – and the amount of resources they are using. Keep an eye out for unidentified processes consuming substantial resources, indicating potential malicious activities.
2. Suspicious Log Entries and Anomalies
Linux:
Monitoring system logs can reveal suspicious activities. Unusual log entries might expose attempts by attackers to obscure their actions. On Linux, you can use the ‘tail’ command to check system logs:
tail -f /var/log/syslogLook for any unfamiliar entries or repeated login failures that could indicate a brute-force attack or unauthorized access.
Windows:
“Event Viewer” is a unique tool that comes with Windows Server that stores pertinent system logs. Press [Win] + [X] to open the Event Viewer, then choose “Event Viewer” from the menu.
Expand the “Windows Logs” section on the left sidebar of the Event Viewer window.
There are multiple log categories available, such as “System,” “Application,” and “Security.” Depending on what you want to look into, click on the relevant log category. Let’s now concentrate on the “Security” log:
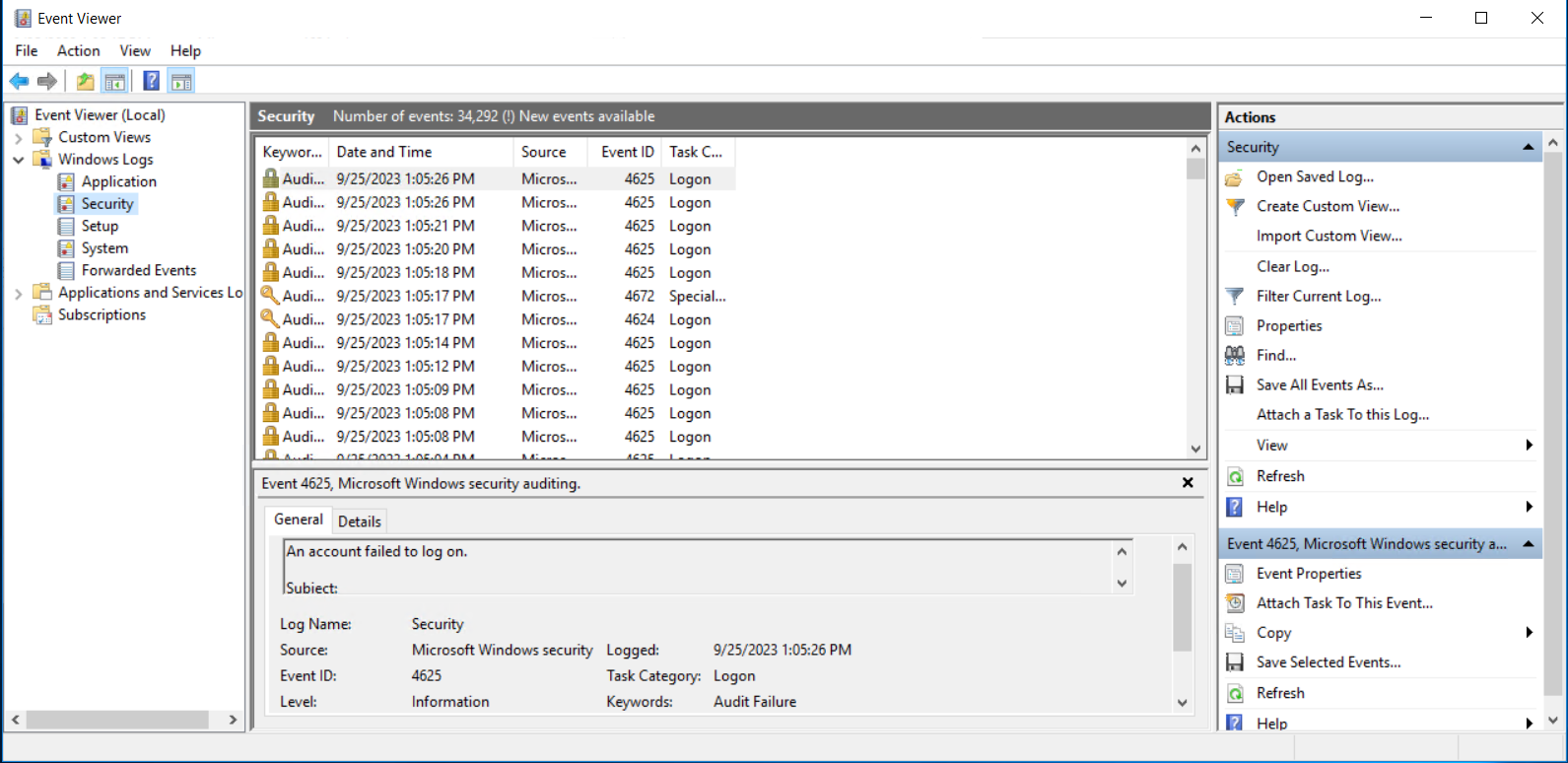
In the “Security” log, you can look for any unfamiliar or suspicious entries. Pay particular attention to repeated login failures, which could indicate brute-force attacks or unauthorized access attempts.
3. Unauthorized Access Attempts and Login Failures
Unauthorized access attempts and unsuccessful login attempts are two more telltale signs that your instance has been compromised. With Linux, the `auth.log` file allows you to examine authentication logs:
cat /var/log/auth.logWatch for recurring login issues or successful logins from strange IP addresses or user names.
These are but a few typical signs of compromise to be on the lookout for. Maintaining the security of your digital environment requires doing routine system monitoring and being on the lookout for these indicators.
Early Warning Signs
While overt system behavior changes are often apparent signs of compromise, more sophisticated attacks might leave subtle traces. This section will explore subtle signs like minor configuration alterations, slight increases in outbound traffic, subtle phishing attempts, and slow and concealed attack methods.
Identifying Subtle Signs of Instance Compromise
Even though unexpected system behavior and decreased performance are frequently clear indicators of a compromise, skilled attackers might leave less noticeable evidence. Among these subdued indicators are:
- Subtle Changes: Tiny, inexplicable adjustments to files, permissions, or system configurations.
- Unusual Outbound Traffic: Minor increases in network traffic leaving the system may be a sign of theft or data exfiltration.
- Phishing Attempts: Subtle phishing attempts include emails that seem suspicious or URLs that might not be immediately apparent.
- Slow and Steady Attacks: In order to evade detection, attackers use “low and slow” tactics, which lessen the visibility of their actions.
Red Flags in System Logs and User Activities
System logs and user activities offer valuable insights into your environment’s security. Red flags to watch for include privilege escalation attempts, suspicious processes with elevated privileges, and unusual account activities happening outside regular hours.
- Privilege Escalation: Unusual requests or actions made by users in an effort to obtain access without authorization or increase their level of privilege.
- Suspicious Processes: Processes that are attempting to access sensitive data or that are operating with elevated privileges are considered suspicious.
- Unusual Account Activity: Creation, modification, or access to accounts outside of regular business hours is considered unusual account activity.
Use security information and event management (SIEM) systems and log analysis tools to help efficiently sort through large volumes of data and spot these red flags.
Detecting Data Breaches
Data breaches can have disastrous effects, including harm to one’s reputation, monetary losses, and legal repercussions. Early detection of data breaches is essential to reducing their impact. This chapter will cover how to spot indicators of data exfiltration, keep an eye out for illegal access to private information, and use anomaly detection to help find data breaches.
Recognizing Signs of Data Exfiltration
The unapproved transfer of data from your network to an outside location under cybercriminals’ control is known as data exfiltration. Look for the following indicators of data exfiltration:
- Unusual Outbound Traffic: Keep an eye on network traffic for any sudden increases in data leaving the system, particularly to unknown IP addresses, strange ports, or recently registered or automatically generated domains ending in “.xyz” or a similar format.
- Large File Transfers: Monitor file transfer activity, especially when sensitive data is involved, and be on the lookout for unusually large or frequent transfers. However, bear in mind that when it comes to obtaining your data, hackers may be patient. They might finish in a few weeks or even months.
- Data Encryption: Keep an eye out for unexpected encryption processes because attackers may encrypt exfiltrated data to evade detection.
You can identify and counteract attempts at data exfiltration by putting data loss prevention (DLP) solutions and network traffic analysis tools into practice.
Monitoring for Unauthorized Access to Sensitive Data
Data breaches often start with unauthorized access to sensitive data. Here are some suggestions for keeping an eye on such things:
- Access Control and Permission Audits: Make sure that only authorized users have access to sensitive data by routinely reviewing access controls and permissions.
- User Behavior Analytics (UBA): Use User Behavior Analytics (UBA) solutions to identify anomalous behavior patterns, like data copying or unauthorized access, by analyzing user activities.
- File Integrity Monitoring (FIM): Keep an eye on important configuration files using FIM tools, and report any unauthorized changes.
The Role of Anomaly Detection in Data Breach Detection
Finding anomalies is essential to detecting data breaches. It entails creating a reference point for typical system behavior and then highlighting departures from it. Important areas for anomaly detection consist of:
- User Behavior: Notice odd locations, times, and access patterns.
- Network Traffic: Look for irregularities in the volume, protocols, and patterns of traffic.
- Application Behavior: Keep an eye out for unusual application usage patterns, like strange database queries or API calls.
- File Activity: Spot atypical modifications to directories, files, or file access patterns.
Recognizing External Threats
Potential attackers may pose an external threat to your instance at any time. We’ll look at warning indicators for these external threats, techniques for blocking and monitoring malicious IP addresses and domains, and tactics for handling denial-of-service (DoS) attacks.
Signs of External Attackers Targeting Your Instance
It’s critical to keep an eye out for any indications that outside attackers could be aiming for your instance. Among the typical indicators are:
- Port Scanning: Port scanning is the practice of making consecutive, frequent connection attempts on different ports, which may indicate that attackers are searching for weaknesses.
- Suspicious Login Activity: Several unsuccessful attempts to log in, especially from different IP addresses or locations, are suspicious login activity.
- Unusual Traffic Patterns: Unusual traffic patterns, like a sudden spike in requests for a particular service, or a sudden increase in traffic.
Monitoring for Malicious IP Addresses and Domains
It’s critical to watch out for malicious IP addresses and domains in order to safeguard your instance. To do this, you can:
- Using Blocklists: To filter out traffic from known malicious sources, use reputable IP and domain blocklists.
- Utilizing Intrusion Detection Systems (IDS): Using Intrusion Detection Systems (IDS): Putting IDS solutions into practice to find and stop traffic coming from IPs that are acting maliciously.
- DNS Filtering: Using DNS filtering services to block access to malicious domains is known as DNS filtering.
Identifying and Responding to Denial-of-Service (DoS) Attacks
DoS attacks can cause your instance to become unresponsive by flooding it with traffic.
Common DoS Attacks 1
Here are the main types of DoS attacks:
| DoS Attack Type | Explanation |
| Ping Flood | Sending an overwhelming number of ICMP Echo Request (ping) packets to a target, causing network congestion and potentially making the target unresponsive. |
| SYN Flood | Exploiting the TCP three-way handshake process by sending a flood of SYN requests to a target, overwhelming its resources, and preventing legitimate connections. |
| UDP Flood | Flooding a target with a high volume of UDP packets, often with spoofed source IP addresses, to consume its bandwidth and resources. |
| HTTP Flood | Overloading a web server by sending an excessive number of HTTP requests, making it unable to serve genuine users. |
| ICMP Flood | Flooding a target with ICMP Echo Request (ping) packets, like Ping Flood, causes network congestion. |
| DNS Amplification | Abusing open DNS resolvers by sending small DNS queries with a spoofed source IP, causing the resolver to send larger responses to the victim, amplifying the attack. |
Common DoS Attacks 2
| NTP Amplification | Utilizing vulnerable Network Time Protocol (NTP) servers to amplify traffic towards a target, creating a DoS situation. |
| Smurf Attack | Broadcasting ICMP Echo Request packets to a network, causing numerous responses to flood the victim’s network. |
| Slowloris | Keeping multiple HTTP connections to a web server open by sending partial HTTP requests, tying up server resources. |
| Teardrop Attack | Sending malformed IP packets with overlapping fragments to crash the target’s operating system or network stack. |
| Application Layer | Targeting application vulnerabilities, such as SQL Injection or Buffer Overflow, to disrupt services or crash the application. |
| Ping of Death | Sending an oversized ICMP Echo Request packet, exceeding the maximum allowed packet size, causing buffer overflows and potential system crashes. |
| DNS Flood | Flooding a DNS server with a high volume of DNS queries, potentially causing it to become unresponsive. |
| HTTP POST Flood | Overloading a web server with a large number of HTTP POST requests, consuming server resources. |
Let’s now discuss how to recognize and handle denial-of-service (DoS) attacks:
- Watch for Traffic Spikes: Sudden, significant spikes in incoming traffic could indicate a denial-of-service attack.
- Leverage Built-In DDoS Protection: Profit from Server Gigabit’s In-Built DDoS Protection. By automatically identifying and thwarting DoS attacks, our system makes sure your instance is always reachable.
Incident Response Plan
It is not a luxury but rather a need to have a strong incident response plan (IRP) in the increasingly connected digital world. We will now examine the procedure for creating an incident response plan, stress the need of having a clearly defined incident response team, and list the critical actions that must be taken in the event that an indication of compromise is discovered.
Developing an Incident Response Plan (IRP)
An incident response plan (IRP) is a detailed plan that describes what your company will do in the event of a security incident. The following crucial actions are involved in creating an effective IRP:
- Risk Assessment: Determine the possible threats and weaknesses that your company may encounter by conducting a risk assessment.
- Team Formation: Create a thorough plan that specifies what to do in the event of a security incident.
- Plan Creation: Develop a detailed plan outlining the procedures to follow when a security incident occurs.
- Testing and Training: Make sure your team has received the necessary training, and test the plan on a regular basis using simulated incidents.
- Documentation: To improve the IRP over time, keep thorough records of incidents, solutions, and lessons discovered.
- Communication: To keep stakeholders informed during an incident, establish communication protocols.
Steps to Take When an Indicator of Compromise is Detected
It is imperative to take prompt and decisive action upon detection of an indicator of compromise (IoC). These are the essential actions to take:
- Isolation: To stop the incident from spreading, isolate the impacted systems or networks right away.
- Analysis: To determine the type and extent of the incident, look into the IoC (indicators of compromise).
- Containment: Developing a plan to stop the incident and stop more damage is known as containment.
- Eradication: Ensure that vulnerabilities are patched and remove the threat from systems that are impacted.
- Recovery: Return impacted services and systems to regular operation.
- Lessons Learned: To find opportunities for enhancement in your IRP and overall security posture, perform a post-incident analysis.
We will go into more detail about containment tactics in the upcoming chapter.
Containment and Mitigation
In order to limit damage and return things to normal, this chapter covers the crucial actions of isolating the compromised instance, turning off compromised accounts and access points, and deleting malicious software and files.
Isolating the Compromised Instance
The first and most crucial step in containing the incident is to isolate the compromised instance. Isolation reduces the incident’s impact on other systems and stops it from propagating farther throughout your network. Here are some suggestions for achieving that:
- Network Segmentation: To ensure that the compromised instance is unable to communicate with other systems, use network segmentation to isolate it from the rest of your network.
- Isolation Protocols: Physically or via network configurations, cut off the compromised instance from the network completely.
Disabling Compromised Accounts and Access Points
You must disable compromised accounts and access points to stop additional unauthorized access and actions. It includes:
- Account Lockout: Disabling compromised or possibly unauthorized user accounts is known as account lockout.
- Password Resets: In order to prevent malicious use of the impacted accounts, initiate password resets for those users.
- Access Point Closure: Seal off any openings, like backdoors, that intruders might have exploited to get inside.
Removing Malicious Software and Files
The next step is to eliminate malicious software and files after you have disabled impacted accounts and isolated the compromised instance. This procedure consists of:
- Antivirus Scans: To find and eliminate malicious software, perform comprehensive antivirus and anti-malware scans on the compromised instance.
- File Cleanup: Examine and remove potentially harmful or suspicious files from the system by hand.
- Patch and Update: To remove potential vulnerabilities that have been exploited, make sure that the compromised instance, as well as any impacted software or systems, are updated and patched.
Maintaining regular backups is essential to preventing data loss in the event of an instance compromise. Consequently, it is wise to have appropriate backup plans.
Investigation and Analysis
One step in preventing future security incidents of this nature is to carry out a comprehensive investigation and analysis of the event. The following procedures will help you perform a post-incident analysis, collect logs and evidence for forensic examination, and determine the compromise’s primary cause.
Conducting a Thorough Post-Incident Analysis
Conducting a thorough post-incident analysis comes next, following the containment of the incident and the mitigation of any immediate threats. This aids in your comprehension of the incident’s entire scope, effects, and lessons for future prevention. Among the analysis’s crucial phases are:
- Document Everything: Keep track of the incident’s detection date, containment strategy, and response actions.
- Interviews: To get information and viewpoints on the incident, speak with all parties involved, such as your incident response team, the impacted users, and IT staff.
- Timeline Reconstruction: Make a timeline that outlines every stage of the incident, from the first compromise to its containment.
- Identify Affected Assets: Ascertain which resources, data, and systems were impacted, possibly compromised, or otherwise compromised.
Gathering Evidence and Logs for Forensic Analysis
You must collect and keep all pertinent logs and evidence in order to determine the scope of the incident and to compile proof for any future legal or regulatory requirements. This procedure entails:
- Log Collection: Take logs from network devices, impacted systems, and any other pertinent sources, and store them securely.
- Network Traffic Capture: For further analysis, if applicable, record network traffic during the incident.
Identifying the Root Cause of the Instance Compromise
Analyzing the compromise’s underlying cause is a crucial component of post-incident analysis. Take the following actions to find the root cause:
- Vulnerability Assessment: Look for weaknesses in the system and network that the attacker might have exploited.
- Incident Reconstruction: Utilizing the timeline and available evidence, reconstruct the incident and determine the attacker’s point of entry and movement within your environment.
Prevention and Hardening
Strengthening the security posture of your instance and averting more security incidents are continuous processes. This chapter will cover how to make your instance more secure, how to put best practices into practice for future protection, and how important it is to continuously monitor and improve security.
Strengthening Your Instance’s Security Posture
Improving the security posture of your instance is a proactive way to lessen vulnerabilities and discourage possible attackers. Important tactics comprise:
- Access Control: To guarantee the least privilege principle, review and adjust user access and permissions.
- Regular Updates: To fix known vulnerabilities, keep your software and system up to date with security patches.
- Firewalls and Intrusion Detection: Detect suspicious activity and filter network traffic by implementing intrusion detection systems and firewalls.
- Secure Configuration: Configure your systems securely by following industry standards and best practices.
- Security Awareness Training: To reduce human error, teach your staff and users security best practices.
Implementing Best Practices for Future Protection
Securing your future involves adhering to best practices that fortify your security measures. These practices encompass:
- Regular Patching: Devise a structured process for patch management ensuring timely deployment of security updates.
- Testing: Prior to implementing patches in production systems, conduct thorough testing in a controlled environment.
- Prioritization: Give precedence to patching by weighing the severity of vulnerabilities and the importance of affected systems.
- Vendor Notifications: Stay updated on security updates released by software vendors and promptly integrate them.
- Backup and Recovery: Maintain consistent backups of critical data to enable swift recovery in the event of a security breach.
Continuous Security Monitoring and Improvement
Sustaining security involves perpetual vigilance and continual improvements. Key steps include:
- Vulnerability Scanning: Routinely scan your networks and systems to pinpoint vulnerabilities that may need attention.
- Log Analysis: Analyze system logs for any indications of unusual behavior or potential security threats.
- Intrusion Detection: Employ proactive intrusion detection systems to swiftly identify and counteract real-time threats.
- Security Metrics: Establish and utilize pivotal security metrics to gauge and ameliorate your security stance progressively.
Conclusion
The inevitability of a security incident underscores the need for proactive measures. Building and upholding a robust incident response plan, forming a proficient response team, and consistently applying security best practices significantly enhance safeguarding your digital assets.
Vigilance and a security-first approach must always lead your digital initiatives. Cyber threats evolve incessantly, with attackers increasingly sophisticated. Staying informed about emerging threats, regularly evaluating, and fortifying your security protocols are imperative actions. Cultivating a culture of cybersecurity awareness within your organization acts as a formidable defense against persistent risks.
Indeed, cybersecurity is an ongoing voyage without a universal fix. It requires dedication, adaptability, and a steadfast commitment to outmaneuver potential threats.